--서브쿼리에 대한 개념. selet절 서브쿼리 활용
SELECT TO_CHAR(A.DT1,'YYYYMMDD') DATE1 --상위쿼리
FROM ( --하위쿼리
select to_date('20210101','YYYY-MM-DD') DT1
,TO_DATE('20220101','YYYY-MM-DD') DT2
FROM DUAL
) A
;
--먼저 SEELCT FROM문으로 컬럼 두개가 만들어졌고 이 부분을 묶어서 테이블에 저장한 테이블이라고 생각.
--만든 SELECT문을 테이블 하나라고 생각하고 FROM절 안에 넣고 A라고 테이블에 별칭 선언.
--=== > 지금 FROM절에 들어가있는데 테이블이 아닌 SELECT문으로 작성한 데이터라고 생각하면됨. (안쪽에 작성되어있기때문에 "하위쿼리"라 부름)
--여기서 A.DT만 출력하면 A라는테이블의 DT1만 출력하면 FROM절에서 데이터 꺼내온거랑 똑같다.
/*SELECT절의 서브쿼리*/
--전체급여 합산한거를 모든열에 넣어서 쓰고싶음.
SELECT SUM(SALARY) AS 전체급여 FROM EMPLOYEES; --여기서 표시된 전체급여 합산액을
SELECT EMPLOYEES.*
, (SELECT SUM(SALARY) AS 전체급여 FROM EMPLOYEES) AS 전체급여 -- *,SALARY 하면 에러남. 결과를 반환할수잇는방법능ㄴ *앞에 테이블명칭을 붙여줘야함.
--이렇게 셀렉트문으로 계산한 데이터를 그대로 가져오게되면 로우데이터를 건들지않고 구간별비중이나 특별한 계산을 해서 파생컬럼을 만들수있는 장점이 존재.
, (SELECT MAX(SALARY) AS 전체급여 FROM EMPLOYEES) AS 최대급여
, (SELECT MIN(SALARY) AS 전체급여 FROM EMPLOYEES) AS 최소급여
, (SELECT COUNT(SALARY) AS 전체급여 FROM EMPLOYEES) AS 직원수
, (SELECT ROUND(AVG(SALARY),2) AS 전체급여 FROM EMPLOYEES) AS 평균급여 --ROUND를 AVG바로앞에서 제어할수도있고 최상단에서 제어할수도있음.
FROM EMPLOYEES;
--셀렉트절의 서브쿼리는 서브쿼리가 셀렉트절로 확장되었다고 해서 스칼럿서브쿼리라고 블림
--출력되는 행수만큼 반복되어 실행된다
--같은 SQL이 반복되어 실행되면서 데이터를 반복해서 출력하므로 성능을 위해 첫번째 행인 100번사원의 데이터를 출력할때 나머지 출력한 데이터를 메모리에 올려놓고
--두번째행부터는메모리에 올려놓은 데이터를 출력하게된다 -- 이러한행위를 서브쿼리캐싱 이라고함.
--이와같은결과를 WINDOW함수를 통해서 출력할수있음.
--윈도우 함수 : 그룹합수 뒤에 OVER라는 함수를 통해 집계하게 됨.
--OVER 정리 : 쿼리 결과 집합 내의 윈도우 또는 사용자 지정 행 집합을 정의한다.
SELECT EMPLOYEES.*
, (SELECT SUM(SALARY) AS 전체급여 FROM EMPLOYEES) AS 전체급여 -- *,SALARY 하면 에러남. 결과를 반환할수잇는방법능ㄴ *앞에 테이블명칭을 붙여줘야함.
--이렇게 셀렉트문으로 계산한 데이터를 그대로 가져오게되면 로우데이터를 건들지않고 구간별비중이나 특별한 계산을 해서 파생컬럼을 만들수있는 장점이 존재.
, (SELECT MAX(SALARY) AS 전체급여 FROM EMPLOYEES) AS 최대급여
, (SELECT MIN(SALARY) AS 전체급여 FROM EMPLOYEES) AS 최소급여
, (SELECT COUNT(SALARY) AS 전체급여 FROM EMPLOYEES) AS 직원수
, (SELECT ROUND(AVG(SALARY),2) AS 전체급여 FROM EMPLOYEES) AS 평균급여 --ROUND를 AVG바로앞에서 제어할수도있고 최상단에서 제어할수도있음.
, SUM(SALARY) OVER () AS 전체급여1 --전체직원의 누적함수를 구할수있음.
, MAX(SALARY) OVER () AS 최대급여1
, MIN(SALARY) OVER () AS 최소급여1
, COUNT(SALARY) OVER () AS 직원수
, ROUND(AVG(SALARY) OVER (),2) AS 평균급여1
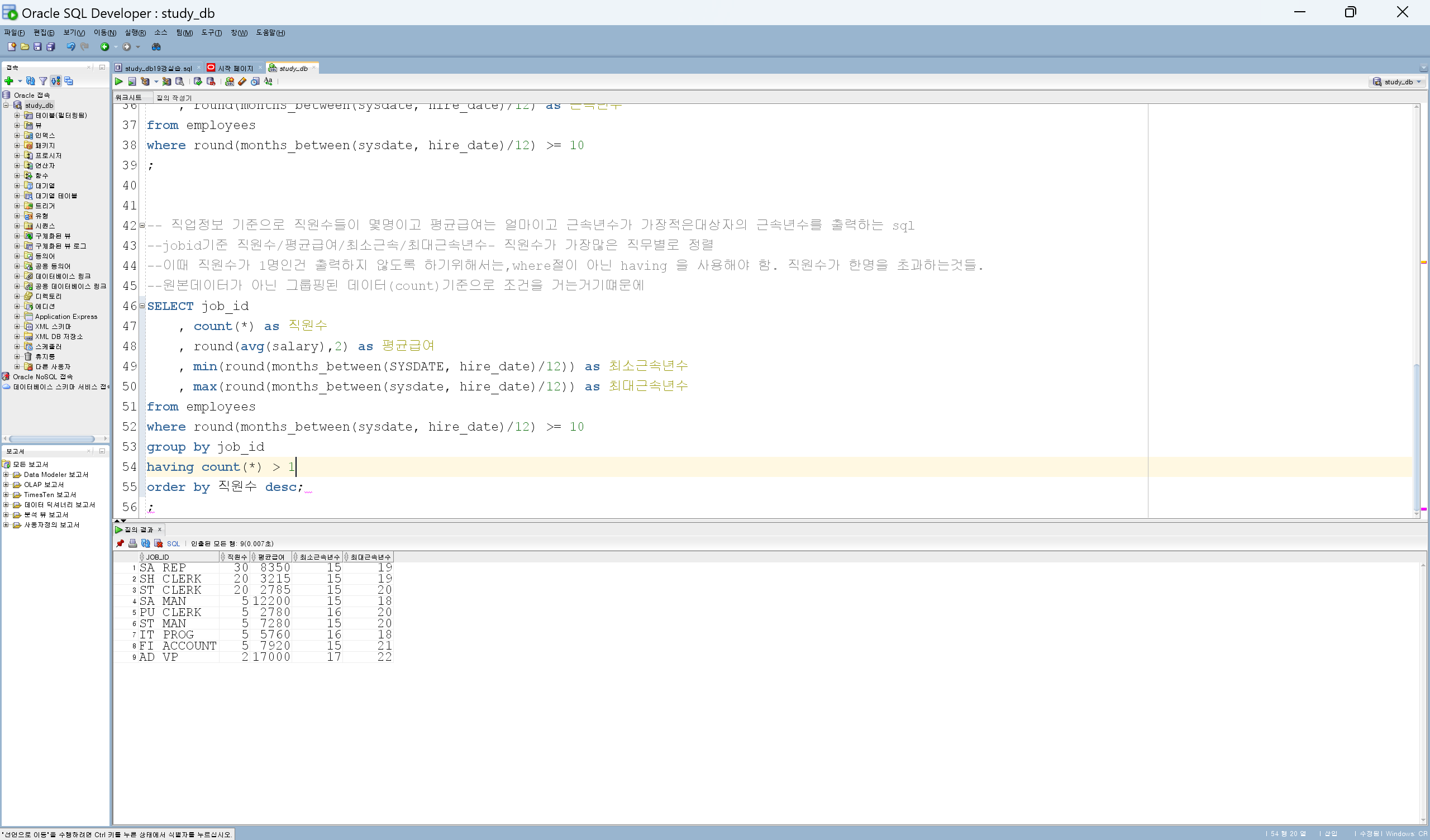
FROM EMPLOYEES;
--부서별 금액합계를 구했을때 JOIN또는 서브쿼리를 통해서 출력할수도 있지만 윈도우함수로도 출력할수있음.
SELECT DEPARTMENT_ID, SUM(SALARY) AS 부서별금액
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
;
--기준을 주게되면 기준별 집계의 결과를 확인할수도 있음. PARTITIONN BY 사용.
--PARTITION BY 정리 : 특정 열을 기준으로 데이터를 나눈다. PARTITION_BY를 지정하지 않으면 쿼리 결과 집합의 모든 행이 단일 그룹으로 취급된다-모두 같은 값을 표시.
--SUM/MAX/MIN/COUNT/AVG의 파티션을 지정해주면 그 파티션 그룹내의 합산/최대/최소/갯수/평균 값들을 표시해줄수 있다는것.
--이때 단점은 같은 동선에 GROUPBY가 쓰일수 없다는 점.
--윈도우함수를 사용해서 상위쿼리로 올라가서 누적집계를 했다면 그룹핑을하거나 다른 작업에 필요한 순간에 상위쿼리로 올라가서 작업을 해야한다는거.
--누적집계를 구할때는 셀렉트절 서브쿼리보다 윈도우함수를 쓰는게 유연하고 쿼리도 깔끔함.
--누적집계만 구할수있는건 아니고, 다른테이블의 컬럼과 정보를 조회해서 가져올수도 있음!! 일종의 SELECT 절에서 조인하는거라고 생각할수있음.
SELECT EMPLOYEES.*
, (SELECT SUM(SALARY) AS 전체급여 FROM EMPLOYEES) AS 전체급여 -- *,SALARY 하면 에러남. 결과를 반환할수잇는방법능ㄴ *앞에 테이블명칭을 붙여줘야함.
--이렇게 셀렉트문으로 계산한 데이터를 그대로 가져오게되면 로우데이터를 건들지않고 구간별비중이나 특별한 계산을 해서 파생컬럼을 만들수있는 장점이 존재.
, (SELECT MAX(SALARY) AS 전체급여 FROM EMPLOYEES) AS 최대급여
, (SELECT MIN(SALARY) AS 전체급여 FROM EMPLOYEES) AS 최소급여
, (SELECT COUNT(SALARY) AS 전체급여 FROM EMPLOYEES) AS 직원수
, (SELECT ROUND(AVG(SALARY),2) AS 전체급여 FROM EMPLOYEES) AS 평균급여 --ROUND를 AVG바로앞에서 제어할수도있고 최상단에서 제어할수도있음.
, SUM(SALARY) OVER (PARTITION BY DEPARTMENT_ID) AS 전체급여1
, MAX(SALARY) OVER () AS 최대급여1
, MIN(SALARY) OVER () AS 최소급여1
, COUNT(SALARY) OVER () AS 직원수
, ROUND(AVG(SALARY) OVER (),2) AS 평균급여1
FROM EMPLOYEES;
--누적집계만 구할수있는건 아니고, 다른테이블의 컬럼과 정보를 조회해서 가져올수도 있음!! 일종의 SELECT 절에서 조인하는거라고 생각할수있음.
--
SELECT (SELECT SUM(SALARY) AS 전체급여 FROM EMPLOYEES) AS 전체급여 -- *,SALARY 하면 에러남. 결과를 반환할수잇는방법능ㄴ *앞에 테이블명칭을 붙여줘야함.
--이렇게 셀렉트문으로 계산한 데이터를 그대로 가져오게되면 로우데이터를 건들지않고 구간별비중이나 특별한 계산을 해서 파생컬럼을 만들수있는 장점이 존재.
, (SELECT MAX(SALARY) AS 전체급여 FROM EMPLOYEES) AS 최대급여
, (SELECT MIN(SALARY) AS 전체급여 FROM EMPLOYEES) AS 최소급여
, (SELECT COUNT(SALARY) AS 전체급여 FROM EMPLOYEES) AS 직원수
, (SELECT ROUND(AVG(SALARY),2) AS 전체급여 FROM EMPLOYEES) AS 평균급여 --ROUND를 AVG바로앞에서 제어할수도있고 최상단에서 제어할수도있음.
, SUM(SALARY) OVER (PARTITION BY DEPARTMENT_ID) AS 전체급여1
, MAX(SALARY) OVER () AS 최대급여1
, MIN(SALARY) OVER () AS 최소급여1
, COUNT(SALARY) OVER () AS 직원수
, ROUND(AVG(SALARY) OVER (),2) AS 평균급여1
, (SELECT DEPARTMENT_NAME FROM DEPARTMENTS B WHERE A.DEPARTMENT_ID = B.DEPARTMENT_ID) 부서명
--다른테이블과 메인테이블의 셀렉트절을 통해서 조인을통한 가벽적인 정보도 출력이 가능하다.
FROM EMPLOYEES A;

'📝수업후기 잊지말기 > 빡공단31기 SQL' 카테고리의 다른 글
| Sqld 38회기출강의정리 (0) | 2023.03.08 |
|---|---|
| 빡공단31기 SQL 27강 (0) | 2023.02.27 |
| 빡공단31기 SQL 25강 (1) | 2023.02.25 |
| 빡공단31기 SQL 24강 JOIN차이점 따로 찾아볼것 (0) | 2023.02.24 |
| 빡공단31기 SQL 23강 (0) | 2023.02.23 |