--복함함수 사용하여 데이터 다뤄보기
--
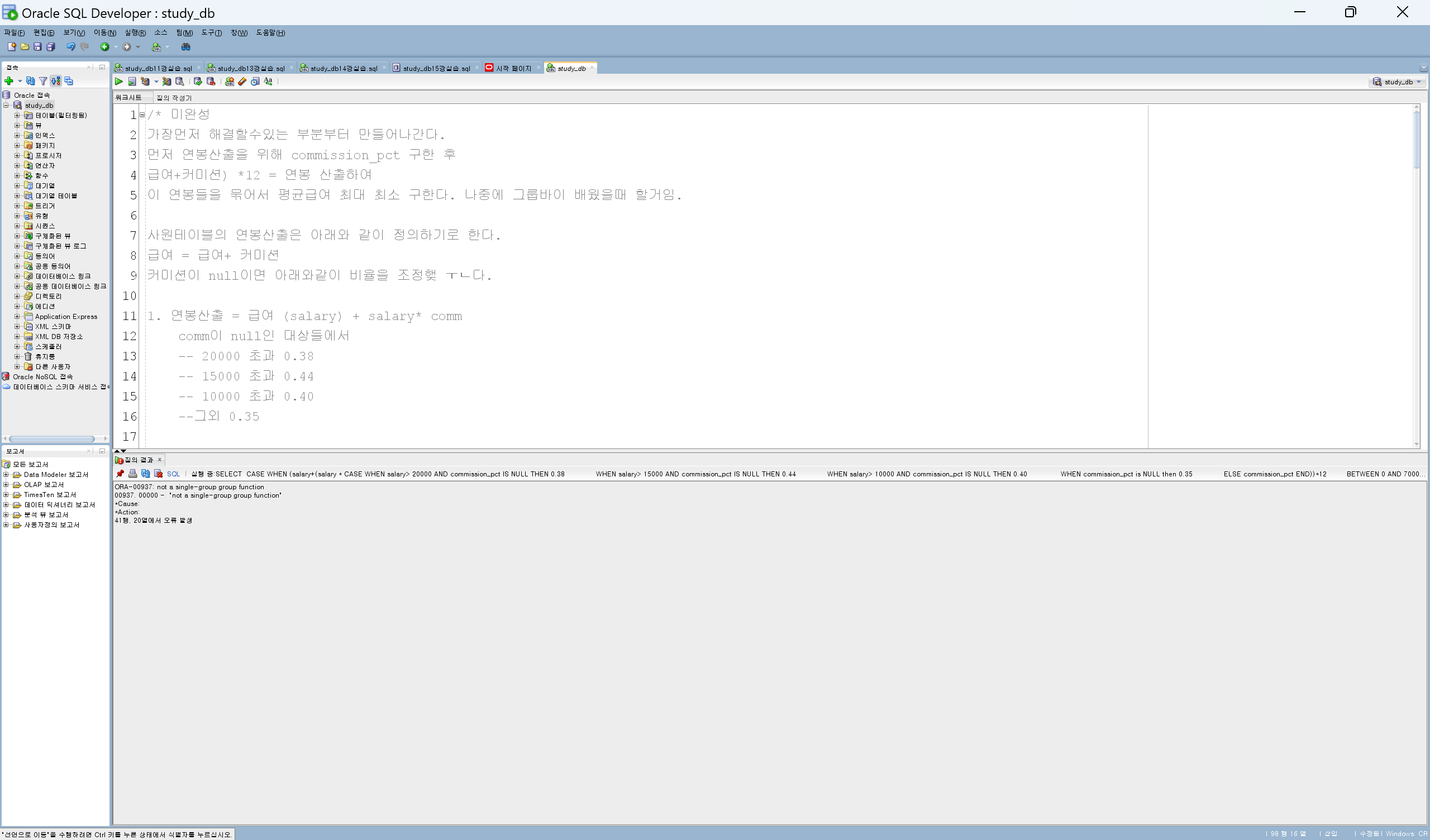
/* SQL 작성순서 및 실행순서
1 SELECT 5
2 FROM 1
3 WHERE 2
4 GROUP BY 3
5 HAVING 4
6 ORDER BY 6
*/
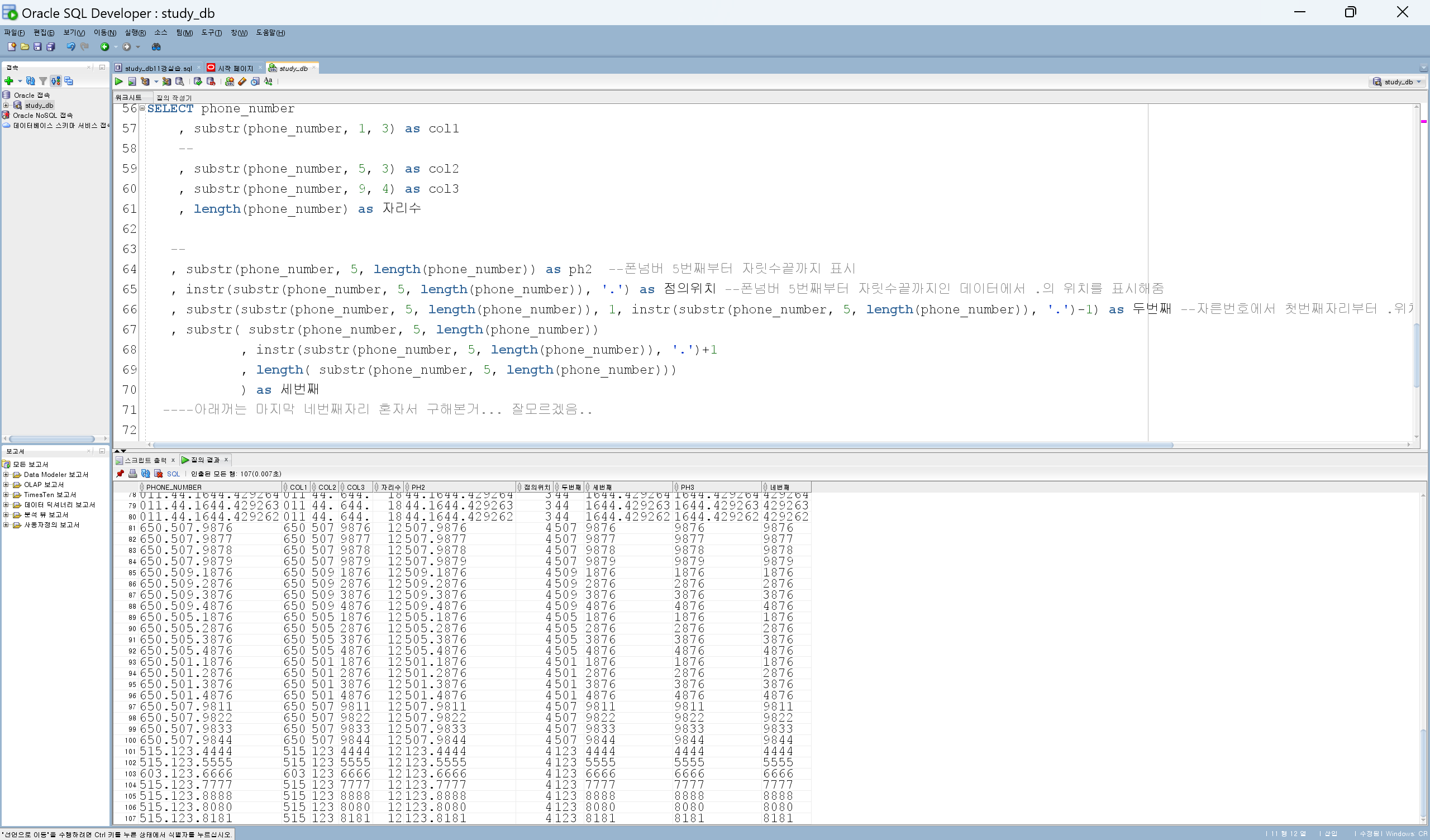
--lpad 활용하여 급여가 가장적은사람부터 많은사람까지 출력. 시각화 구현
SELECT last_name||' '||first_name as emp_name
, to_char(hire_date,'yyyymmdd') as hire_dt
, salary
, department_id
, lpad('■',round(salary/1000,0),'■') as sal_vi
FROM employees
order BY salary desc;
--연도별 입사자 수와 평균 급여 출력하기
SELECT substr(to_char(hire_date,'yyyymmdd'), 1, 4) as 년도
, count(*) as 입사자수
, round(avg(salary),2) as 평균연봉
, lpad('■',count(*),'■') as 입사자_vi
from employees
group by substr(to_char(hire_date,'yyyymmdd'),1,4)
order by 입사자_vi
;
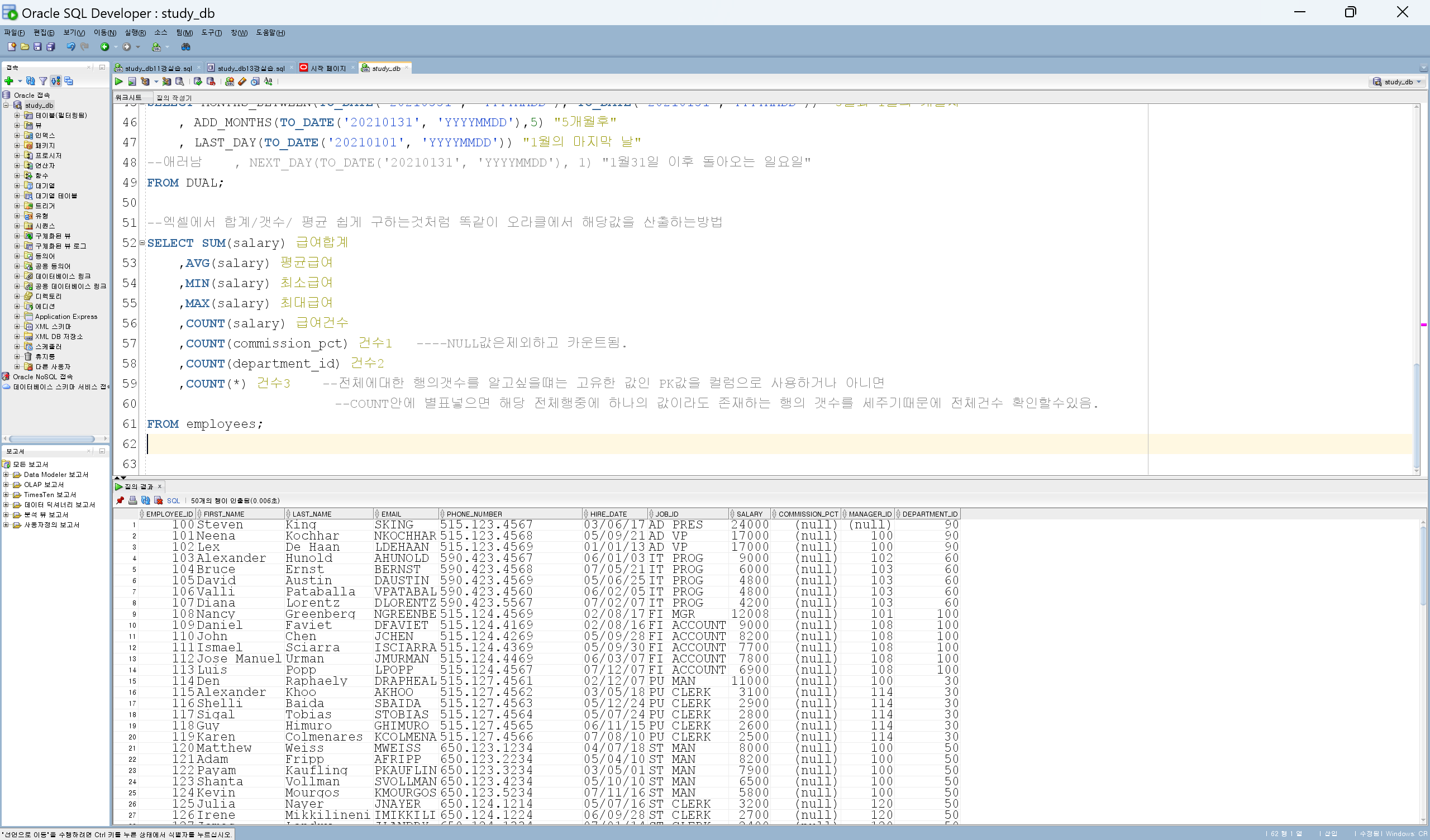
--직원들의 이름, 급여, 부서번호, 직업정보, 근속년수
SELECT last_name||' '||first_name as 이름
, salary as 급여
, department_id as 부서번호
, job_id as 직업정보
, round(months_between(sysdate, hire_date)/12) as 근속년수
from employees
where round(months_between(sysdate, hire_date)/12) >= 10
;
-- 직업정보 기준으로 직원수들이 몇명이고 평균급여는 얼마이고 근속년수가 가장적은대상자의 근속년수를 출력하는 sql
--jobid기준 직원수/평균급여/최소근속/최대근속년수- 직원수가 가장많은 직무별로 정렬
--이때 직원수가 1명인건 출력하지 않도록 하기위해서는,where절이 아닌 having 을 사용해야 함. 직원수가 한명을 초과하는것들.
--원본데이터가 아닌 그룹핑된 데이터(count)기준으로 조건을 거는거기떄문에
SELECT job_id
, count(*) as 직원수
, round(avg(salary),2) as 평균급여
, min(round(months_between(SYSDATE, hire_date)/12)) as 최소근속년수
, max(round(months_between(sysdate, hire_date)/12)) as 최대근속년수
from employees
where round(months_between(sysdate, hire_date)/12) >= 10
group by job_id
having count(*) > 1
order by 직원수 desc;
;

'📝수업후기 잊지말기 > 빡공단31기 SQL' 카테고리의 다른 글
| 빡공단31기 SQL 22강 (0) | 2023.02.22 |
|---|---|
| 빡공단31기 SQL 21강 (0) | 2023.02.21 |
| 빡공단31기 SQL 19강 (0) | 2023.02.19 |
| 빡공단31기 SQL 18강 (0) | 2023.02.18 |
| 빡공단31기 SQL 17강 (0) | 2023.02.17 |